前文提要:2025年末,商业银行不良贷款余额已达3.26万亿元,催收介入的时候,债务人的资产可能已经转移,关联风险早已传导,那扇可以干预的窗口,悄悄关上了——银行对借款人外部真实风险状况的掌握,严重滞后于贷款本身的账面数据。
#银行催收部 #资产管理部 #不良资产处置
金融机构催收的演进与重构
1.0时代,从关系催收到粗放外访

回望2000年代初,国内银行的对公信贷催收主要依赖客户经理的“个人关系”,一笔贷款出了问题,客户经理先给借款人打电话,约出来喝茶,谈还款……谈不下来,再一级级向上汇报,最后走诉讼。
周期基本一年起步,执行回款遥遥无期。
这个阶段,催收的核心能力是 「关系」,信息高度依赖人的经验积累。同一家企业,不同客户经理了解到的风险程度可能完全不同。
粗放,但不复杂,信贷规模有限,不良率的绝对值也不高,很多银行选择“借新还旧”把问题往后推。
2.0时代,系统化与数据孤岛

2010年前后,信用卡消费贷崛起,个人信贷规模急剧扩大,人工催收的效率瓶颈暴露。
银行开始引入催收管理系统CMS,把债务台账、催收记录、案件分配等环节搬到线上,批量外呼系统上线,催收从一对一谈变成一对多打。
这个阶段,催收的核心能力是 「流程」,效率来自标准化作业。
但问题是 数据在各机构内部流转,与外部世界是隔离的。 一家企业的被执行记录在法院系统里,工商信息在市场监管系统里,企业的关联方分布在十几张不同的数据库里。银行只能看到自己系统里的还款记录,看不到借款人在外面的真实风险状况。
信息孤岛,是2.0时代的结构性问题。
3.0时代:合规重塑与数据基础设施重建

2021年是一个转折点。
《个人信息保护法》、《数据安全法》相继落地,对数据采集和使用划定了严格边界,对过度采集债务人信息、暴力催收等行为被明令禁止,催收行业被迫从粗放走向规范。
2026年1月,中国银行业协会发布《金融机构个人消费类贷款催收工作指引(试行)》,对催收时间、频率、方式、AI催收的技术公平性等做出全面规范。

监管的逻辑很清楚——催收是可以做的,但要在合规框架内,用合理的方式进行。
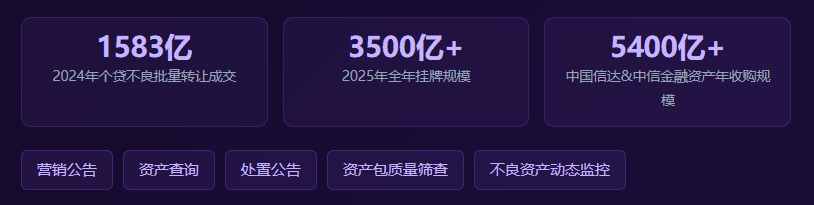
合规成本在上升,但另一个趋势也在加速——不良资产的处置市场正在快速扩容。2024年个贷不良批量转让成交1583亿元,2025年全年挂牌超3500亿元,仅中国信达与中信金融资产两家AMC年收购规模就超5400亿元。

规模放大的背后,是一个效率问题:AMC要买,银行要卖,但资产包里有多少是真正可回收的有价值资产,有多少是空壳公司或早已资不抵债的垃圾资产,批量尽调的效率和准确性,直接决定了转让定价的合理性。
这个效率问题,贯穿了1.0、2.0、3.0三个时代,到现在依然没有完全解决。
区别在于3.0时代,解决这个问题的工具变了。
外部数据基础设施在过去五年快速成熟——工商、司法、知识产权、招投标、舆情等多维度市场主体数据覆盖,AI技术让数据查询从人工翻档案变成自然语言提问,信息孤岛正在被打破,但谁先接入,谁就先拿到优势。
催收这件事,正在被重新定义
一笔对公贷款逾期90天,客户经理翻出借款企业的联系方式,打过去,无人接听,上门去注册地址,发现那是一栋早已清退的写字楼。
企业工商登记状态显示“存续”,但实际控制人名下还有哪些公司,这些公司有没有被起诉、有没有被执行,档案里看不到。
这笔不良,最后打折转给了AMC。转让的那一刻,没有人知道如果早三个月介入,结果会不会不一样。
这不是某一家银行的问题,这是整个行业在面对的,一道结构性的信息差。
另一边,不良资产的处置市场正在快速扩容,“合规”与“效率”,正在成为催收工作的两条并行主线。
而这两条主线背后,都指向同一个基础设施问题:数据够不够及时,够不够全。
催收效率的本质,是一个信息对称问题
为什么数据对催收这么重要?
先看一组数字。
2025年四季度末,商业银行不良贷款余额3.5万亿元,较年初增长约1000亿元。不良率约1.5%,看似不高,但考虑到信贷规模的基数,实际新增的不良资产体量相当惊人。
这些不良资产最终流向两个出口:要么银行自己催,要么打包转让给AMC。
无论走哪条路,都面临同一个问题——银行对借款人的信息掌握程度,往往远低于对贷款本身账面数据的了解。
账面数据是结构化的,涉及到**贷款金额、利率、期限、担保方式,**但借款人的真实风险状况是分散的:在外面有没有被起诉?有没有被执行?实控人名下还有没有其他公司?这些公司之间有没有互保关系?资产有没有已经被抵押出去了?
这些信息分布在工商、司法、知识产权、招投标、舆情等多个系统里,不主动去查,根本不知道。
而催收的时机,往往就卡在「不知道」和「知道了」之间。
现实中大量案例表明很多债务人并不是没有能力还,而是有意转移资产后选择不还,等到催收介入时,企业账户早已清空,名下资产早已抵押或转让,查封执行回款聊胜于无。
这不是催收人员不努力,这是信息获取的时点太晚了。

另一个结构性问题是 关联风险。
借款企业A本身看起来正常,但实控人控制的B公司已经被执行,B对C有担保关系,C又在与A相同的地址办公。这类关联传导在传统信贷管理里几乎没有被前置识别,等到A也出现违约时,损失已经扩散了。
催收工作中有一个信息窗口期的概念——从风险信号出现到损失真正形成,中间有一段可以被干预的时间。
但这个窗口期的有效性,完全取决于信息到达的速度,如果风险信号滞后才被人工发现,窗口期早就关闭了。
数据的作用,就是在窗口期之内把信息送到决策者面前。
工商变更、司法案件、股权质押、资产查封——这些信号单独看都是零散的,但连在一起,就是一家企业真实风险状况的全景图。
当这套全景图在贷款发放时就存在,在贷后管理中持续更新,在催收介入前就已生成,催收策略的制定依据就不再是催收人员的个人经验,而是「完整的风险画像」。
这个转变,才是数据真正改变催收效率的核心逻辑。
催收业务流程里的四个信息盲区
银行催收工作通常分为三个阶段:贷后监控、深度催收、处置回收。每个阶段,都存在信息不对称的典型盲区。
盲区一:贷后监控滞后
大部分银行的贷后管理还处于定期翻档案阶段,每季度或半年翻一次还款记录,没有逾期就默认正常。
但很多风险信号不等季度性报告。
更隐蔽的是关联企业风险。借款企业本身还在正常经营,但同一实控人名下的另一家公司正在被法院执行,或者刚刚被吊销。这种关联传导在传统贷后管理里几乎没有触发条件。

批量导入存量客户清单,持续监控风险情况,任意一项触发即推送预警至客户经理,无需人工定期查询。
盲区二:催前尽调信息不足
一笔贷款进入M1(逾期1-30天)阶段,催收人员拿到企业名称,能看到的基本信息有限。
真实的风险藏在看不见的地方,比如一家借款企业本身看起来正常,但实控人名下其他公司已经被执行了多条记录,或者实控人本人已经收到限制高消费令。这类信息在催收介入前如果能获取,催收策略会完全不同。

支持新增逾期客户一键尽调,生成完整风险画像。
盲区三:债务人失联
企业的备案网站、APP、小程序,招聘网站的联系方式,分支机构的地址,历史变更记录里留下的旧地址,都是可以追溯的触达路径。关联方的触达同样是突破口——股东、主要人员任职信息、上下游合作伙伴,甚至担保人,都可能成为重新建立联系的节点。

从单一企业出发,拓展催收线索网络。
盲区四:不良资产处置效率
进入处置阶段,意味着回收率已经开始打折。但资产包里往往混入了大量看起来有债权、实际无资产可执行的空壳公司,尽调成本高,处置周期被拉长。
一家企业注册地址异常、零纳税、零社保、频繁变更法人——这类特征组合在一起,基本可以判断为空壳,不值得花费催收资源。而另一部分企业虽然表面正常,但动产抵押记录显示设备已被抵押,股权出质记录显示股权早已质押,这类资产线索直接影响回收价值的判断。

企业财税数据支撑回收价值评估,帮助识别高价值和低价值资产,分层处理,提高处置效率。
某互联网银行催收部是怎么做的?
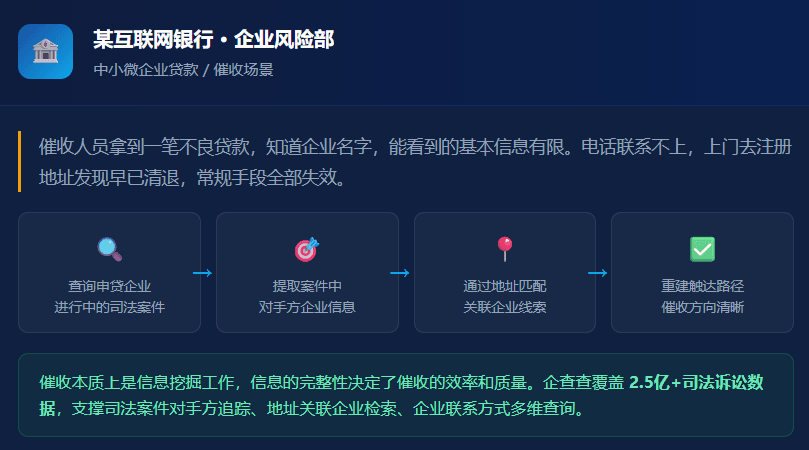
在过往合作中,该银行企业风险部在日常催收工作中遇到一个问题:催收人员拿到一笔不良贷款,知道企业名字,能看到的基本信息有限。
他们的做法是收集申贷企业有进行中的司法案件,里面藏着对手方企业,这个对手方的联系方式、地址、主要人员,是催收可以直接用的线索,同地址的其他关联企业,同样是线索。
通过申贷企业找到当前在审/在执的司法案件,提取对手方企业及其联系方式;通过地址字段匹配,找到同地址的其他关联企业。线索一旦拉出来,催收的方向就清晰了。
这个场景的底层逻辑是——催收本质上是信息挖掘工作,信息的完整性决定了催收的效率和质量。
AI如何融入催收环节
企查查MCP智能体数据平台,是一个专为AI智能体和大模型打造的企业数据基座,通过MCP协议和CLI命令行双栖接入,180个原子工具分布在6大Server:
| Server | 工具数 | 覆盖数据 |
|---|---|---|
| 企业基座 | 16个 | 工商登记结构化数据:股东、实控人、财务数据等 |
| 风控大脑 | 35个 | 失信/被执行/严重违法/税务异常等核心红线,触发即熔断 |
| 知识引擎 | 18个 | 专利/商标/软著/数字资产矩阵全维度 |
| 经营罗盘 | 35个 | 招投标/融资租赁/信用评价/资质/舆情/土地动态等 |
| 历史存档(认证企业专享) | 34个 | 追溯历史股东/法代/失信轨迹,识别「洗白型」主体,企业专享 |
| 董监高画像 | 42个 | 以人查风险,个人司法风险+关联企业穿透、受益所有人识别等 |
对于有AI应用规划的机构,这意味着在行内AI对话系统里直接问 「这家企业有没有被执行记录」 或 「帮我扫描这个实控人名下的关联风险」,系统实时调用对应工具返回结果,催收人员不需要切换系统,不需要手动查询,AI直接给出结论。
值得一提的是,这套平台内置了实体强锚定机制——大模型常见的企业主体混淆问题(比如把乐视影业查成乐视网),通过强制信用代码验证来规避;同时全面实施参数下推,引导AI按需索取数据而非全量返回,显著降低Token消耗,对行内AI系统的集成成本更友好。

这个能力对于人力有限的城商行和农商行特别有价值——客户经理不需要学习专业系统,用日常语言提问,就能拿到结构化的风险信息。
催收这件事,长期被简单理解为打电话和上门,但真正做过催收的人都清楚,催收的本质是一场信息战,谁更早拿到债务人完整的信息图谱,谁就握住了回收的主动权。
监管在收紧,合规成本在上升,但技术也在给出新的解题思路。
让风险信号比债务人先到,这是数据能做的事。

产品能力对照
根据不同的业务场景和接入需求,企查查提供四套数据服务方案,可灵活匹配各类金融机构的技术能力和预算:

| 数据场景 | 核心能力 | 典型应用 |
|---|---|---|
| 贷后监控 | 工商变更、失信/被执行新增、经营异常、司法拍卖、股权冻结 | 风险信号触发即推送,替代人工定期查询 |
| 催前尽调 | 合作风险排查(34类风险一次查)、实控人穿透、关联企业扫描 | 新增逾期客户一键生成风险画像 |
| 失联修复 | 联系方式挖掘、地址关联企业、关联方追溯 | 拓展催收线索网络,重新触达债务人 |
| 不良资产处置 | 空壳扫描、资产线索挖掘、企业财税评估 | 批量识别高/低价值资产,分层处置 |
| AMC对接 | AMC营销公告监控、资产包质量筛查 | 快速对接转让需求,提升资产盘活效率 |
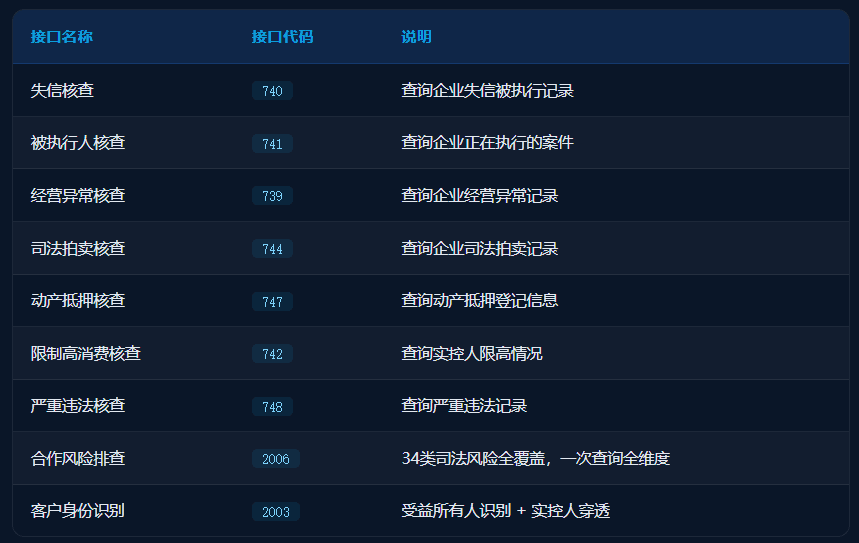
常用API接口参考:
来源引用:
[1] 国家金融监督管理总局,《2025年四季度银行业金融机构主要监管指标数据》,2026年2月12日
[2] 银登中心,《2024年不良贷款转让业务统计》,2025年
[3] 财联社,《两大全国性AMC年收购不良资产超5400亿》,2026年4月
[4] 中国银行业协会,《金融机构个人消费类贷款催收工作指引(试行)》,2026年1月30日
[5] 国家金融监督管理总局,《金融机构合规管理办法》,2024年12月25日



